


新闻中心
NEWS center
一、什么是信号数据
01、信号数据介绍
信号数据:
- 由终端设备生成
- 带有信号采集生成或发送的时间(单位可以是到秒/毫秒/微秒等级别的精度,现在毫秒较常见)
- 包括一个或多个传感器信号值、控制器状态值、或软件代码逻辑生成的一些计算结果值
- 以Hz形容频率,n Hz = 1/n秒,1Hz = 1秒一行,10Hz = 0.1秒或100毫秒一行, 100Hz = 0.01秒或10毫秒一行
原始信号形态是稀疏的(sparse):
- 稀疏的意思是在每一个时间点,仅有很少比例的信号有值(其余为空)
- 稀疏的原因是各个传感器/控制器/软件采集生成信号的频率是各自独立的- 设备越复杂,传感器/控制器/软件代码越多,信号越多,所以更稀疏
- 采集原始信号的硬件通常叫Logger

原始信号可以通过重采样(resample)变成非稀疏的(dense):
- 重采样是基于原始数据在另一个频率上填充
- 重采样通常是频率低于原始频率,填充常用的方法是就近值,以如下为例:
• 原始数据是100Hz(10毫秒一行信号),重采样在10Hz(100毫秒一行)
• 信号就会按照填充的逻辑每100毫秒生成一行信号值
• 因为重采样频率低于原始信号10倍,会减少信号的数据量(10行-》1行)
• 经过填充后,原来空值的信号列就会被填上他们的就近值
- 车端T-Box设备通常会做重采样再上传
02、原始信号 vs 重采样信号
原始信号被重采样后有特征精度丢失的问题:
- 重采样频率越低,特征精度丢失越严重
- 看采样点的就近值落在什么地方,甚至会造成错误的结论
对于客户来讲用原始信号vs重采样有个性价比平衡的问题:
- 信号越原始计算结果的可信度越高(模型越精准)
- 信号越原始数据量越大(1Hz -> 10Hz = 10倍数据量)
• 车端/云端计算资源成本
• 车端/云端存储空间成本
• 网络流量成本
• IT部门人员平台系统维护成本
• 业务部门等待计算完成的时间成本
存储原始信号:
- 云端:仅适合试验车辆(车不多但数据精度要求原始)
- 车端:开始涌现的需求(平衡计算精度/问题溯源需求和上传存储的成本控制)
03、常见的车内信号传输的通讯协议
CAN总线:控制器局域网(Controller Area Network):
- 1986 年德国电气商博世公司开发出的面向汽车的通信协议
- CAN 信号包:一个信号包里可以有1到8个byte字节的数据
- CANFD 信号包:新一点,支持一个信号包里可以有最多64个byte字节的数据
- 信号包为二进制,需要配合一个信号定义文件(DBC)才能解析,DBC里写了字节怎么解析,转换的计算公式等
SOME/IP:车内以太网常见的协议,AUTOSAR Adaptive 框架里的一部分:
- 本质上是以太网TCP/UDP上面封装的一个应用协议 ̶不用解析信号,收到的时候已经是解析好的值
04、常见的车和云信号传输通讯协议
MQTT:IBM发布的一个开源轻量级协议:
- 长连接
- 通过broker的多对多通讯
- 消息订阅机制(publish-subscribe)
HTTP(S):互联网的通用协议:
- TCP短连接
- 一对一通讯
- 请求回答机制(request-response )
05、常见的车内信号序列化的协议
序列化(serialization):将软件内部的数据对象转换成一种可以跨产品/平台可以交互的编码格式:
- 反序列化(deserialization):将通用编码格式的数据转成软件内部的数据对象
- 序列化/反序列化通常为一对
- 常见的序列化/反序列化有protobuf、json、xml
protobuf (protocol buffer):
- 谷歌设计的开源二进制格式
- 谷歌提供大量的跨平台支持,也因为谷歌支持好,有很多设备应用 - 比文本格式精简,但需要预定义好内容
json:
- 计算机/互联网通用的文本描述格式
- 所有系统基本都能支持
- 支持灵活定义内容,解析简单、不需要预定义,现在JSON已经是主流
xml:
- 计算机/互联网通用的文本描述格式
- 所有系统基本都能支持
- 描述格式麻烦,解析代价高
二、信号与传统数据的差异
01、传统数据 vs 信号数据
传统数据:
- 记录业务执行Transaction Result
- 稀疏性低、直接业务属性高
- 例子:股票交易、商品购买、互联网页面点击
传统数据以统计为主的分析
统计不需要顺序
信号数据:
- 记录当前某个采样值 Sampling Value ̶稀疏性高、直接业务属性低
- 无明确行为记录、工况或环境因素,需要通过算法识别/推理
- 例子:车速、温度、方向盘转角度、油门踏板深度、空调开关状态
信号数据按照对象分布+时间顺序逐步分析
对象不一致/顺序颠倒会导致结果错误
分析时将数据按对象分布并维护数据的时间顺序排列:
- 传统数据:大部分情况下没这需求
- 信号数据:大部分情况下是必需
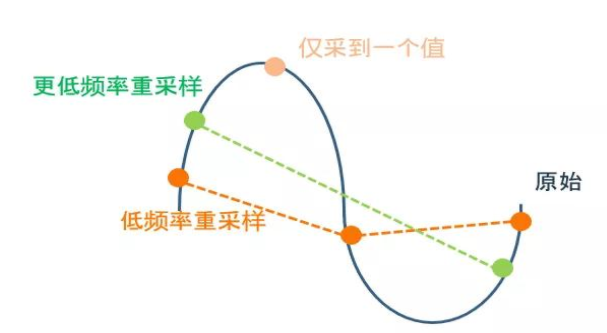
02、明确 vs 识别

乙在10:32时消费了10元,单行数据足够表达明确的有业务意义的行为。

甲在10:30-10:37这段时间内有一个加速的行为,过程里或外任何的单行信号都不足以表达有业务意义的行为,需要按业务逻辑完整识别这段可大可小的过程后再总结计算出隐性表达的行为特征,如这个行为花了7分钟,最大速度差为4公里,为一个缓慢加速的行为。
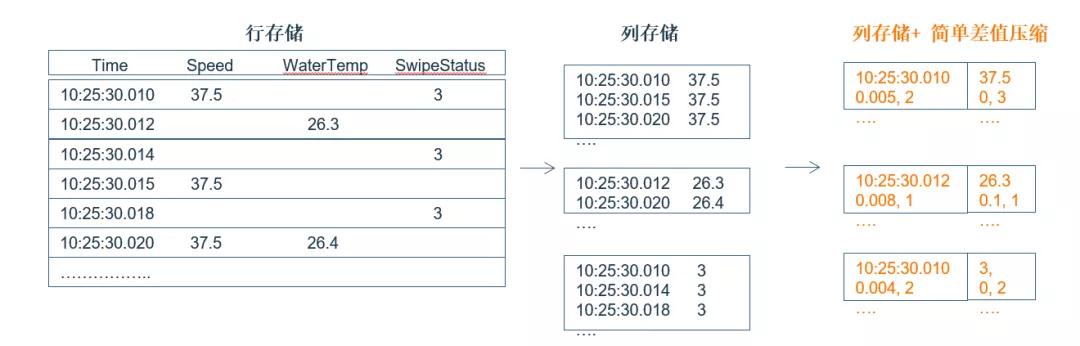
03、行存储
三、互联网计算架构并不适合信号数据
01、计算架构演变史
每几年一个新包装的计算架构或名词出现(分布式计算、深度学习等):
- 一夜之间铺天盖地的宣传,“未来已来”
- 很多人学习推广,套上大概念(大数据、人工智能等)
- 明年换个新名词,再来一遍
- 很少有人问?
• 这个技术领域真的是新的吗?还是40年前就出现过?
• 到底是什么底层的改变使得这个技术领域重新被发现了价值?
事实是:计算架构的改变基本上都是由硬件的提升触发的:
- 当代的计算机硬件可以抽象为算力(CPU/GPU)+ 存储(内存/闪存/磁盘)+ 通讯(以太网/4G/5G)三大块
- 在任何一个时间点上/面对一个复杂的业务需求,算力/存储/通讯里至少有一个是不够用的,“软件架构的存在就是为了弥补不足的那些块
- 每5-10年当算力/存储/通讯其中的一块发生了较大提升的时候,“不够用”会移到没提升的块,要解决的问题变了,“新”架构出现
• 存储速度提升 + 网络带宽不够-》把计算步骤按照数据存储地逐步指派,移计算不移数据(Teradata,1970s)
• 算力提升+ 存储空间不够-》用算力配合存储格式改变来做压缩(Vertica, 1990s)
• 网络带宽提升 +单机算力不够-》同样的计算步骤发到所有数据节点上,数据节点即为计算节点,通过网络分布大数据块并行计算(Hadoop, 2000s)
• 网络吞吐量提升 +集群算力不够-》存储计算节点分离,网络化存储读写,细分存储格式,加上云平台虚拟机/容器的灵活扩展去实现理论上无限的并发(Snowflake)
02、分布式 ≠ 分布式
- 计算和数据位置绑定,优化出分布式的多步执行步骤(Teradata)
- 数据通过中间件的管理实现共享,分布式执行需要锁保障(Oracle RAC)
- 数据节点各自是独立的单机系统(可以单独调用的节点),通过语法层或客户端来解析数据位置,工作分到节点独立执行再合并(Greenplum、EXD vData)
- 同样的计算步骤分到所有数据节点上同时执行,实际运算时如果数据不在节点通过网络读取(Hadoop)
- 单点事务,多点复制,一写多读,通过算法保障读的分布式读取的最终一致性(Amazon Aurora)
- 存储计算分离、高压缩格式、动态扩展算力配合微细分区块实现无限并发(Snowflake,EXD Stardust)
03、计算架构现状
今天车联网(物联网)的计算架构是按照互联网计算架构搭建的:
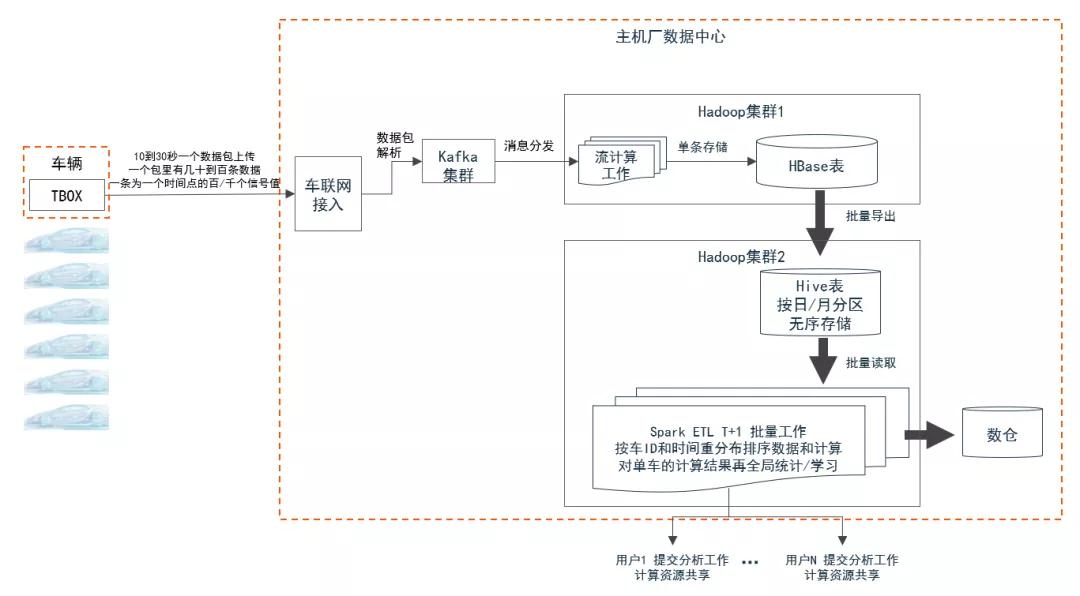
04、互联网计算架构不适合信号数据
高数据存储成本浪费:
- HBase/Hive存一样的数据
- 因为Hadoop x3 多存3份
- 存储成本居高不下
大量计算资源浪费在无用的数据移动与分布排序:
- 流计算拆解数据包
- HBase导出,格式转换,写入Hive
- Spark再重新分布和排序Hive数据
架构不适合车联网/物联网:
- 数据从平台接入到分析延时长(等待T+1 ETL)
• 不仅仅是ETL频率的问题,因为现实中设备上传的信号受限于环境条件,经常会有丢失和重传,ETL频繁重做会很复杂
• 再好的流架构也解决不了小时级别延迟的补传/重传的重新计算
- 分析需要大量计算资源,但受限hadoop计算节点和存储资源绑定的架构,用户普遍资源分配少,长时间等待计算完成
• 多用户一起分析时,计算资源不够
• 用户少的时候hadoop集群是浪费
在汽车智能化水平快速提升的今天,高精度、高质量的信号数据运用逐步成为业务部门的“刚需”,那么首先要解决的问题,就是探索出一种适合信号数据传输利用的全新架构,欢迎各位跟我们一起思考和探讨。

关注我们
联系我们
010-64466266
联系地址:
北京市海淀区知春路27号量子芯座10层
上海市长宁区凯旋路1388号长宁国际发展广场T1栋10层

周一至周五 上午10:00~下午18:00
版权所有 © 2023 智协慧同 All Rights Reserved 京ICP备12027719号-2
联系我们
010-64466266
关注我们
联系我们
电 话:010-64466266
商务合作:info@smartsct.com
地 址:北京市海淀区知春路27号量子芯座10层
上海市长宁区凯旋路1388号长宁国际发展广场T4栋7层
