


新闻中心
NEWS center
随着汽车行业的不断发展,“软件定义汽车”的趋势已然明显。汽车电子电器架构(EEA)由分布式转向域控,再朝着中央集中式等稳步迈进。汽车,已经从吉利董事长李书福所描述的“汽车相当于两张沙发、四个轮子加上一个车壳“,演变成地平线创始人余凯口中的“汽车相当于四个轮子上的超级计算机“。
各主机厂通过打造个性化的智能座舱、越来越高等级的自动驾驶能力,提升用户体验,吸引广大消费者,这其中,自动驾驶无疑是汽车工业皇冠上的明珠。无论是从L2级别的辅助驾驶入局,还是着眼于L4、L5级别的完全自动驾驶,甚至是游离于该分级体系之外的特斯拉FSD系统,各个主机厂和科技公司纷纷大力投入,布局自动驾驶领域。
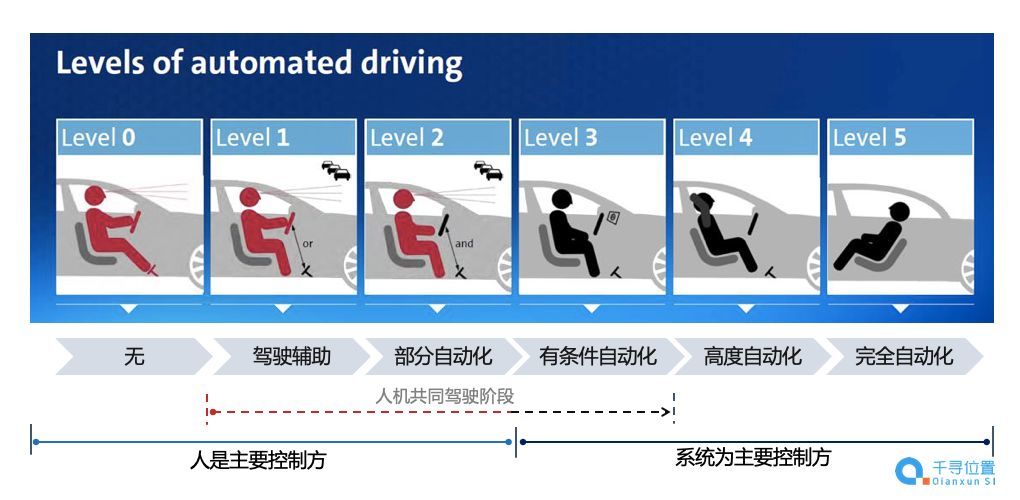
自动驾驶级别示意图
自动驾驶领域离不开车辆的“感知“、”决策“和”控制“,这三个方面环环相扣。其中,汽车对道路等环境的“感知”是基础,这一过程中产生的大量数据,是各个主机厂所迫切需要的“数据原油”,特斯拉通过 “AutoPilot”,已经积累了约百亿英里的行驶数据;蔚来、小鹏等车企也纷纷效仿,采集相关行驶数据。行业共识,数据获取是每个主机厂实现自动驾驶的必经之路,谁拥有了“数据原油”,谁就有可能最先提炼出来用于各个场景能力落地的数据价值。数据,已经成为主机厂和科技企业的必争之地!
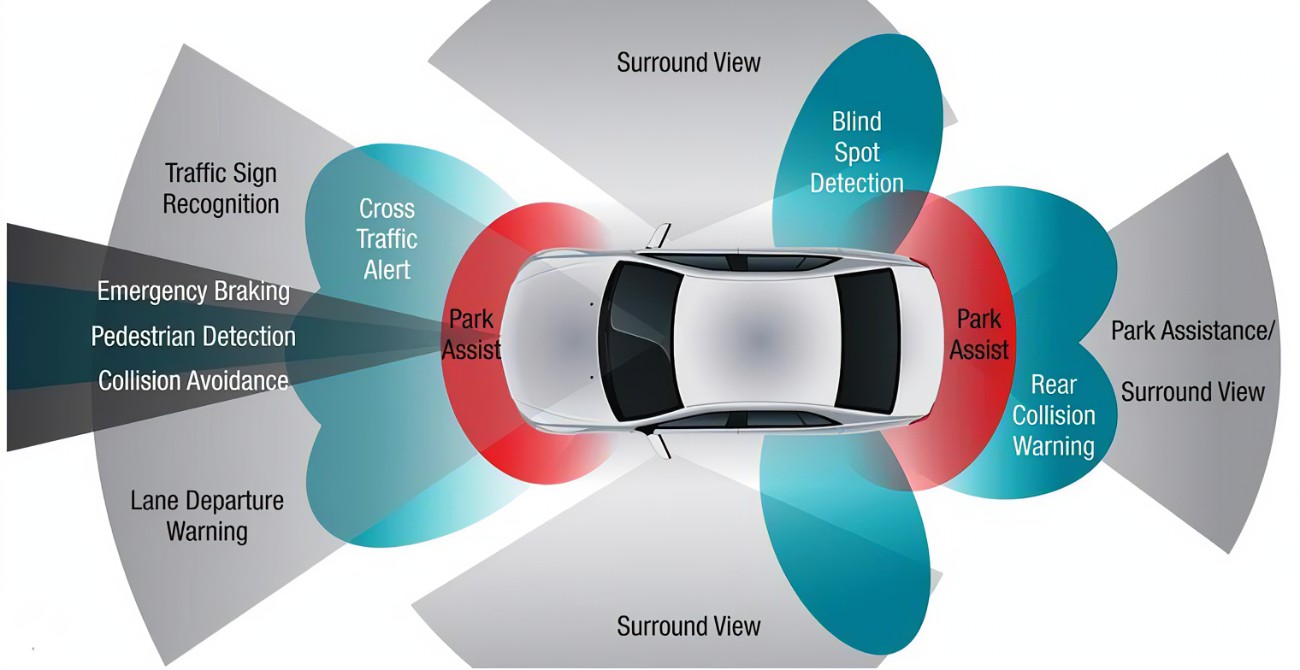
自动驾驶数据采集应用现状
自动驾驶的数据源来自于车身各种传感器的数据,包括车载摄像头、激光雷达、毫米波雷达、超声波雷达等感知数据;同时,车辆本身所产生的总线信号数据等结构化数据,也有助于自动驾驶中的决策与控制。总体来说,我们可以将自动驾驶进程中的数据分为两部分,结构化数据和非结构化数据。针对这两种类型的数据,我们采集和使用的方式有所不同,但都是必不可少的。

非结构化数据多种数据源对比
针对结构化数据的获取,我们一般用数采设备等硬件方式采集,或者通过车联网采集。这两种方式各有优劣,数采盒子采集的数据质量精度很高,但设备昂贵不方便,只能在路测阶段使用,无法用于量产车;车联网方式虽然可以进行量产车数据采集,但囿于网络、带宽、存储等限制,采集的数据价值精度质量低而无法真正发挥其价值。这两种方式的成本都非常高昂。
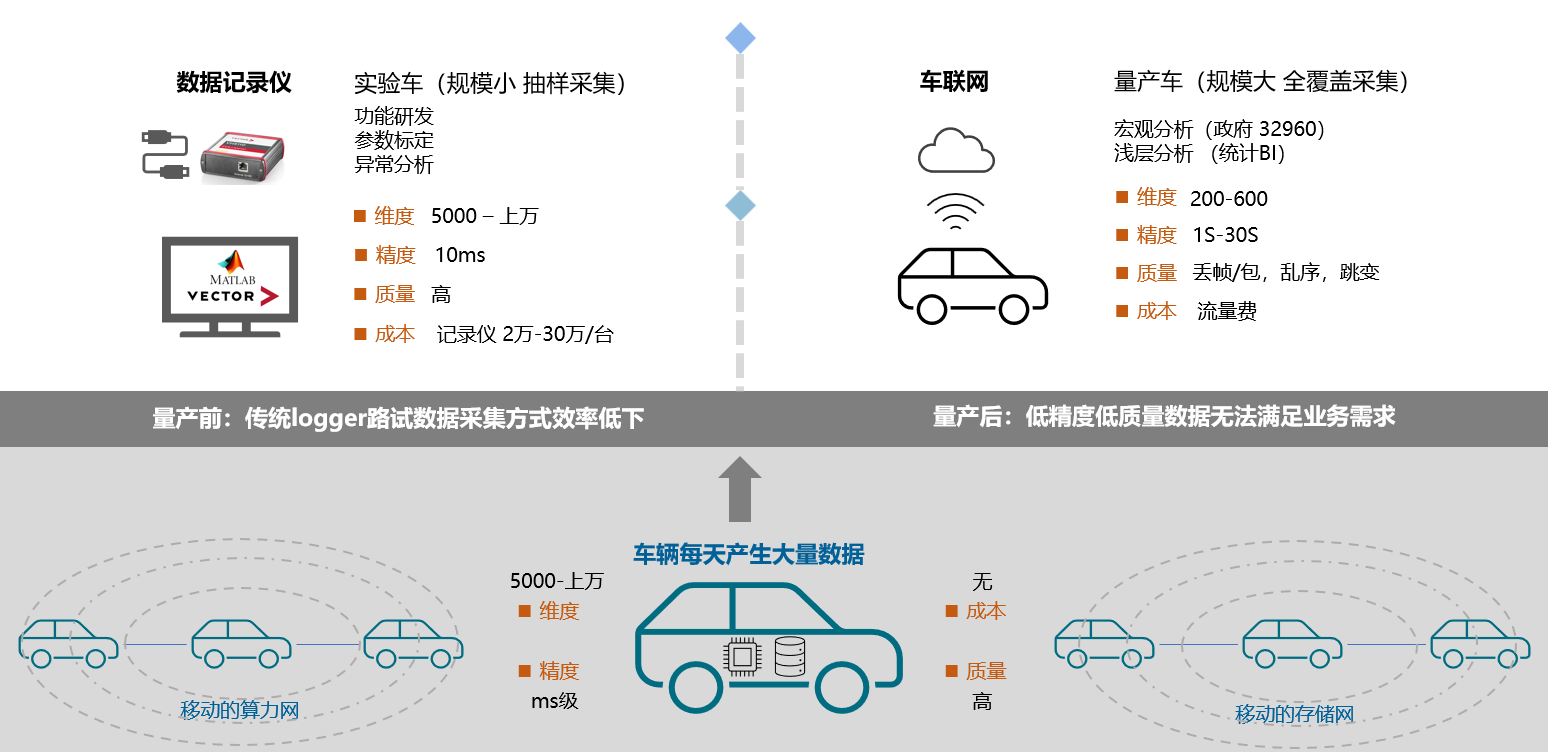
传统结构化数据获取方式
而针对于非结构化数据的采集,目前市面上其他家未见有成熟的方案,自动驾驶领域碰到的“Corner Cases”等各种长尾场景,又因为没有足够多的相关数据,而陷入难以推进的困难局面,这大大提高了自动驾驶开发者的数据获取成本、功能开发成本、时间成本等,降低了研发落地的效率。
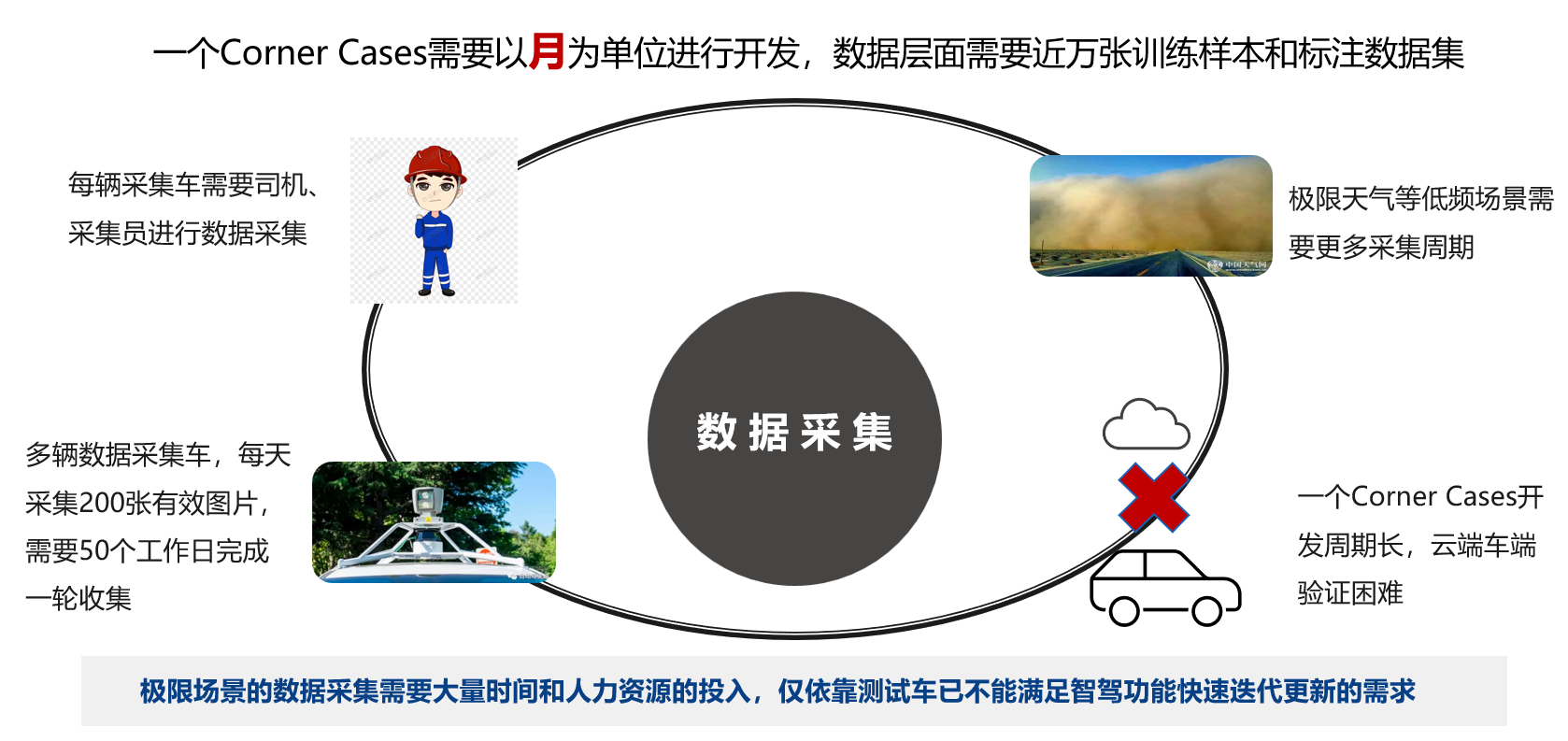
Corner Cases场景解决痛点
针对以上行业获取数据的痛点,智协慧同提供了车云全栈的产品矩阵,用于解决自动驾驶领域车端数据获取的问题。
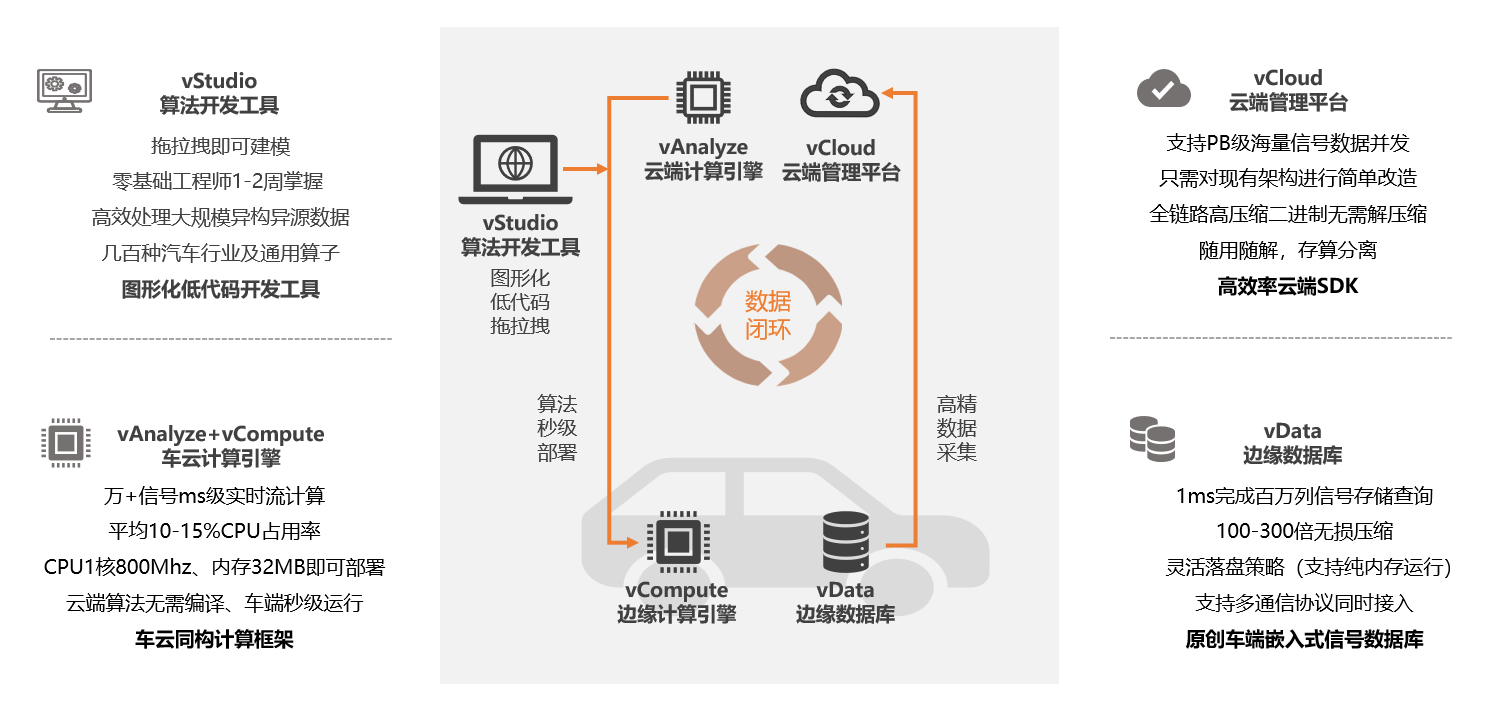
智协慧同提供针对数据获取的车云全栈产品
我们的产品包括拖拉拽式的开发工具vStudio、车云同构的模型运行平台vAnalyze(云端)和vCompute(车端),原创时序车载数据库vData,以及云端数据存储处理平台vCloud。我们具备以下能力:
提供低代码开发平台vStudio,快速进行模型搭建;
轻量化模型一键下发至车端;
车端高质量数据获取;
车端高质量数据上传;
云端模型仿真迭代;
量产车级产品部署模型搭建经验。
智协慧同助力主机厂自动驾驶领域场景能力落地
影子模式
影子模式”首先由特斯拉提出并应用到车端,进行相关决策的对比和触发数据上传。在有人驾驶状态下,系统包括传感器仍然运行但并不参与车辆控制,只是对决策算法进行验证——系统的算法在“影子模式”下做持续模拟决策,并且把决策与驾驶员的行为进行对比,一旦两者不一致,该场景便被判定为“极端工况”,进而触发数据回传。
智协慧同助力主机厂实现影子模式AB模型的一键下发至车端运行,车端模型实时和驾驶员决策信息进行比较,车端计算引擎vCompute会根据比较结果确定是否触发数据采集,车端数据库vData会将相关数据压缩上传至云端,从而实现影子模式触发的数据采集至云端进行分析。

影子模式概念图
Corner Cases
自动驾驶落地的一大阻碍项即是无穷无尽的Corner Cases,这些Corner Cases所带来的安全隐患一直限制着自动驾驶的真正上车。人眼可以对正常车道上出现的意外物体做出反应,但汽车由于算法模型等的限制,可能无法正确做出判断识别。
想要解决这些问题,必须拥有足够多的数据样本以及便捷的车端验证方式。传统方式中,搜集相关场景的数据是一大难题,模型在云端开发完成后,车端适配验证又是一大难题。针对这些难题,智协慧同依靠自己的车云同构产品体系,方便快捷的模型搭建工具,灵活多样的数采触发规则设置,可以实现在车端采集相关场景的数据,上传到云端进行模型训练和场景仿真。这些灵活多变的触发trigger可以通过多种规则模型的设置,实现在车端相关极限场景下的数据搜集和上传,助力主机厂高效解决Corner Cases,从而推动自动驾驶的前进。
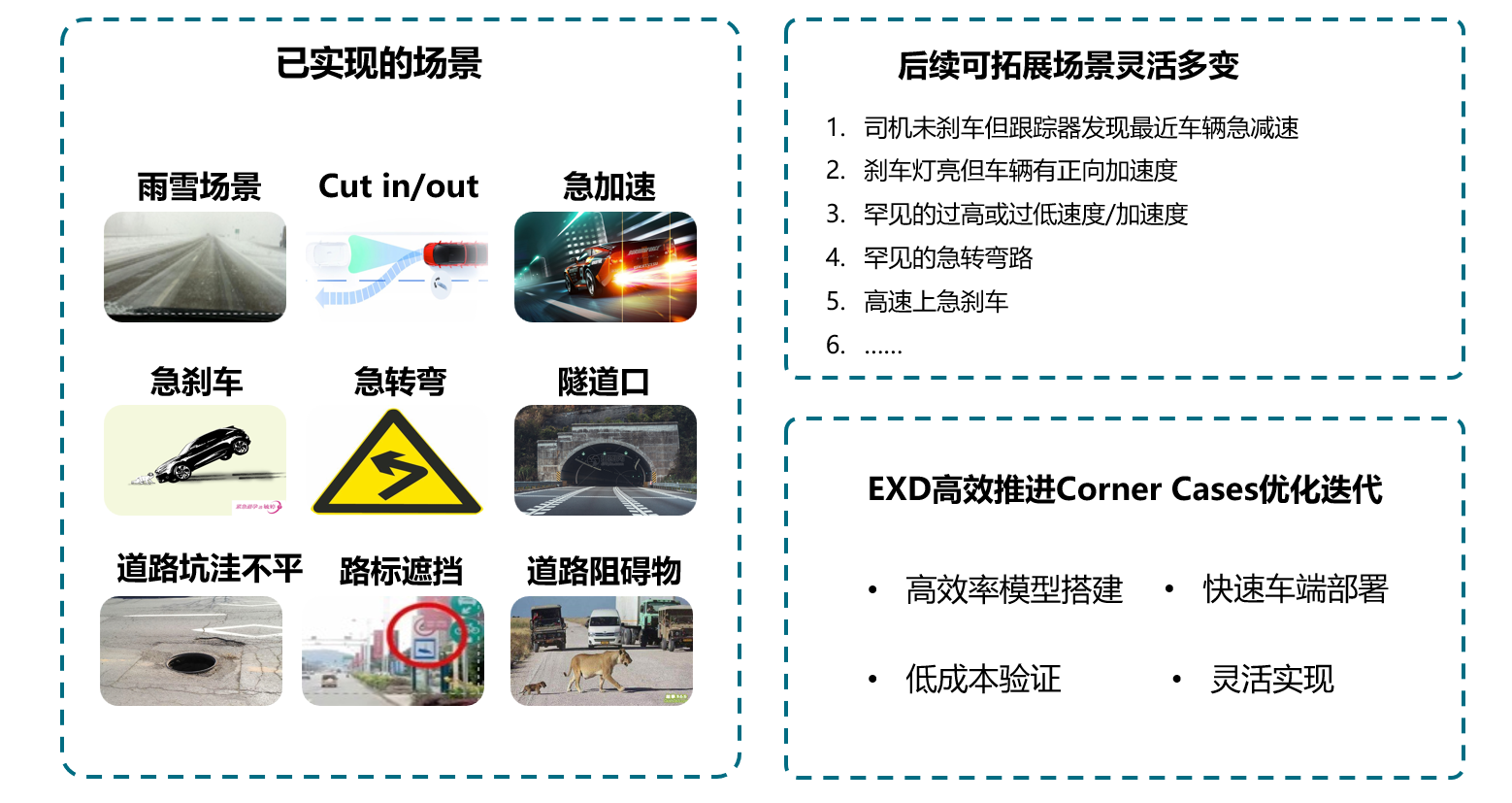
智协慧同方案已获得多家主机厂认可,即将量产落地
在自动驾驶数据闭环这一赛道上,智协慧同已和多家主机厂合作,实现车辆自动驾驶域的数据闭环。
客户A需求项:
需要实现整车测试阶段的图像数据和结构化数据的采集、压缩和上传;
客户的多辆测试车现有硬盘拷贝模式效率较低,无法满足算法快速迭代的要求;
客户需要将影子模式在智驾控制器上进行同步的虚拟感知(障碍物识别等)测试和验证;
客户需要定制化车端的数据采集触发机制和车端边缘技术的算子库,来实现更多场景的精准数据采集。
客户B需求项:
实现多个触发场景的数据采集,包括结构化和非结构化数据采集需求;
实现云端模型下发和车端模型运行;
实现场景触发数采到云端的可视化展示。
根据客户的需求,智协慧同针对性的提出解决方案,并和客户一道打造基于OrinX的自动驾驶域数据闭环方案。
智协慧同销售VP牛国浩提到:”我们有信心有能力为主机厂提供高效低价的自动驾驶数据采集方案,打破行业目前缺乏轻量化方案、价格高昂的现状。“
未来,拥有自动驾驶(辅助)功能的车辆将会迎来大幅度增长;自动驾驶产业链市场广阔,而智能化自动驾驶汽车是AI(人工智能)技术落地的最大应用场景之一;智能化汽车可能成为未来万物互联的终端,成为继智能手机之后,深刻改变社会形态的产品。
在这一关键的历史进程中,智协慧同投身于自动驾驶数据闭环的赛道,伴随着着中国汽车行业的崛起,携手各个主机厂和科技企业,共创智能汽车新未来!

关注我们
联系我们
010-64466266
联系地址:
北京市海淀区知春路27号量子芯座10层
上海市长宁区凯旋路1388号长宁国际发展广场T1栋10层

周一至周五 上午10:00~下午18:00
版权所有 © 2023 智协慧同 All Rights Reserved 京ICP备12027719号-2
联系我们
010-64466266
关注我们
联系我们
电 话:010-64466266
商务合作:info@smartsct.com
地 址:北京市海淀区知春路27号量子芯座10层
上海市长宁区凯旋路1388号长宁国际发展广场T4栋7层
